The memory layer
for
LLM & AI agents.
Tell Claude something in the morning, ask ChatGPT about it at night. Engram gives your AI conversations persistent memory across every platform.
Free · 2-minute setup · Works with Claude & ChatGPT
Most AI memory tools store flat facts and search by similarity. Engram extracts structured knowledge — typed, ranked, and organized — so your agents actually understand what they know.
Open source · 3 API calls · Works with Claude, ChatGPT, and any LLM
Works with
Works with
How it works
Your AI finally remembers.
Tell Claude your preferences in the morning. Ask ChatGPT to pick up where you left off at night. Engram keeps one shared memory across all your AI tools.
"I'm working on a marketing plan for my SaaS launch. Target audience is solo developers. Budget is $5k."
Engram remembers this
Shared memory hub
Always in sync
"What marketing channels should I focus on?"
ChatGPT already has your memory
Switch AI tools freely.
Use Claude for coding, ChatGPT for brainstorming. Your memory follows you. No more repeating yourself.
Picks up where you left off.
Start a conversation on Monday, continue it on Friday. Engram remembers your projects, decisions, and preferences across sessions.
Your data, your control.
See exactly what Engram remembers in your dashboard. Edit, delete, or organize your memories anytime.
See it in action
One memory, two AIs.
Save a memory in Claude, recall it in ChatGPT — and vice versa. Engram keeps your memories in sync across every platform, automatically.
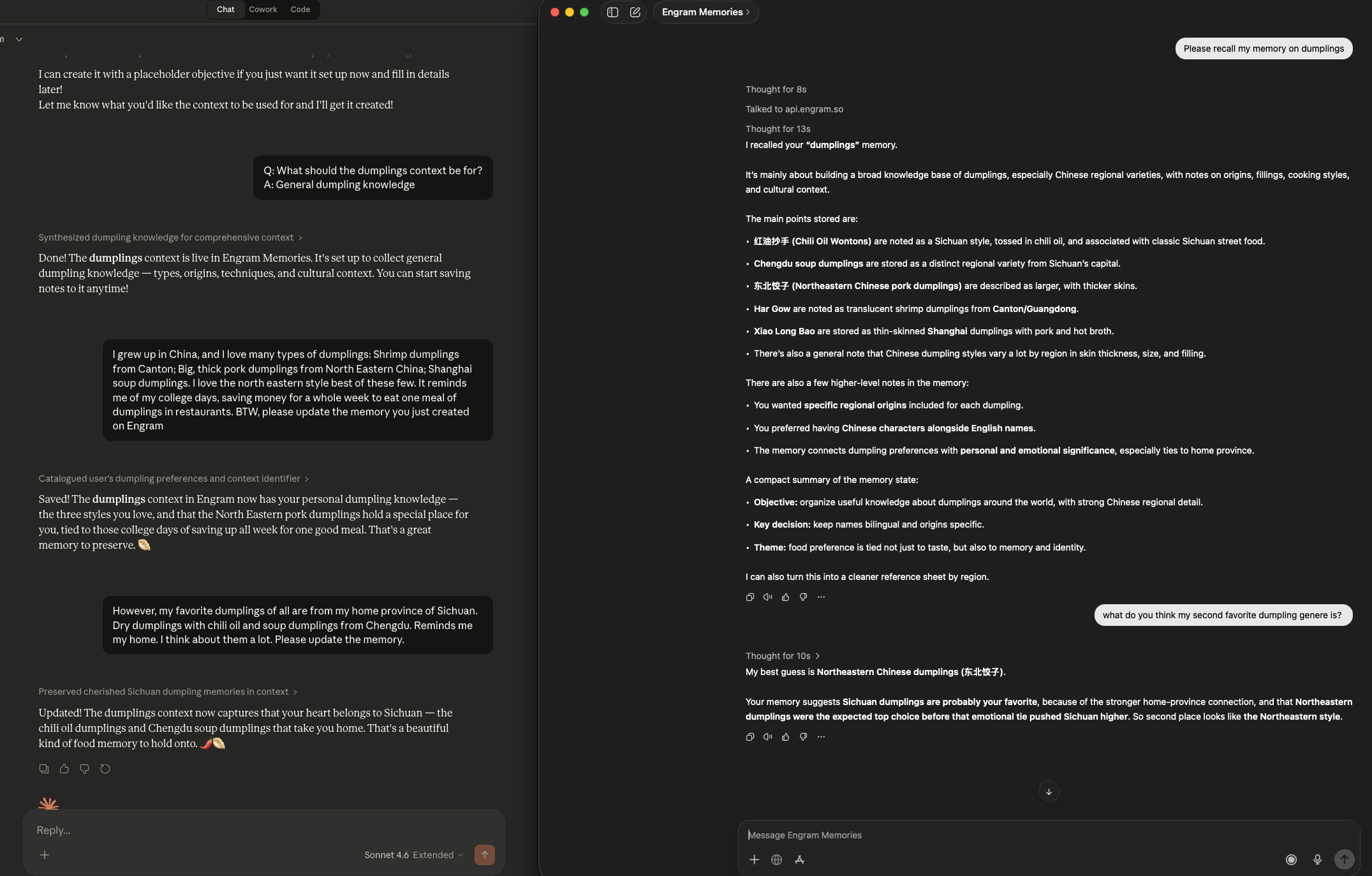
Memory created in Claude (left) → recalled and queried in ChatGPT (right)
Setup
Ready in 2 minutes.
Connect Engram to Claude and ChatGPT. No coding required.
Connect to Claude
Sign up for Engram
Create your free account at app.engram.so
Add as a Connector
In Claude → Feature Preview → Connectors, add Engram using your API key
Start chatting
Claude will automatically remember and recall across sessions
Connect to ChatGPT
Sign up for Engram
Create your free account at app.engram.so
Add the Engram GPT
Search "Engram" in the GPT store, or create a Custom GPT with Engram Actions
Start chatting
ChatGPT will share memory with Claude and other AI tools
Memory is more than a key-value store.
You've probably tried the basics: stuff the chat history in the prompt, bolt on a vector search, or store flat facts in a database. It works — until it doesn't.
10,000 tokens of chat history. Your agent has the information — buried in noise. Costs spike. Latency doubles. And it still misses the one fact that matters.
Your retriever returns "I live in Boston" AND "I moved to Vancouver." Your agent picks one at random. The user corrects it for the third time.
You store 500 facts. Which ones matter right now? They all look the same. No priority, no type, no decay. Your agent dumps everything into the prompt and hopes for the best.
These approaches store information. Engram builds knowledge.
The Solution
What makes Engram different.
Not just storage and retrieval. Engram understands, organizes, and prioritizes what your agent knows.
Every memory has a type.
Engram doesn't store flat strings. Every piece of knowledge is classified — FACT, DECISION, PREFERENCE, GOAL, PROCEDURE, PRINCIPLE — so your agent knows the difference between what a user likes and what they decided.
Not all memories are equal.
Every bullet gets a salience score based on importance and recency. Critical decisions rank higher than casual mentions. Stale knowledge decays over time. Your agent always knows what matters most right now.
Fits your context window.
Tell Engram your token budget. It assembles the most important, most relevant knowledge that fits — not just the most similar. No overflow, no truncation, no wasted tokens.
Handles updates, not just appends.
"I live in Boston" followed by "I moved to Vancouver" doesn't return both. Engram detects the contradiction, supersedes the old fact, and keeps a version history.
Patterns emerge automatically.
After enough conversations, Engram detects recurring patterns and forms schemas: "user prefers concise technical answers" or "team always reviews PRs before merging." Structure emerges from usage.
One memory, every model.
Connect Engram to Claude via MCP, ChatGPT via Actions, or any agent via REST API. Tell Claude something in the morning, ask ChatGPT about it at night. Same knowledge, everywhere.
How it works
Three API calls. Structured memory.
No vector database to manage. No retrieval pipeline to tune. Your agent commits what it learns, recalls what it needs, and knowledge self-organizes over time.
Commit
Your agent saves what it learned.
Raw conversation goes in. Typed, structured knowledge comes out. Facts, decisions, preferences, goals — each extracted, classified, and scored for importance.
curl -X POST api.engram.so/contexts/abc/commit \
-H "Authorization: Bearer eng_..." \
-d '{
"input": "User prefers dark mode,
lives in Vancouver,
runs an AI consultancy"
}'→ Extracted: 3 bullets (FACT, PREFERENCE, DECISION)
→ Superseded: 1 bullet (location: Boston → Vancouver)
→ Salience: 0.85, 0.72, 0.91
Materialize
Your agent recalls what it needs.
Not a similarity search. Engram assembles the most important, most relevant knowledge within your token budget. What comes back is ready to inject into any prompt.
curl -X POST api.engram.so/contexts/abc/materialize \
-H "Authorization: Bearer eng_..." \
-d '{
"query": "user preferences"
}'→ Returned: 12 bullets, 2,400 tokens (budget: 4,000)
→ Ranked by: relevance × salience
→ Includes: 2 schemas, 0 contradictions
Consolidate
Knowledge self-organizes.
Over time, Engram deduplicates, merges related facts, forms schemas from recurring patterns, and decays stale knowledge. Your context stays clean no matter how many conversations flow through.
# Automatic background process
# Dedup, merge, schema formation,
# salience decay, contradiction resolution→ 500 conversations → 47 active bullets, 3 schemas
→ 12 duplicates merged, 2 contradictions resolved
→ 8 stale bullets archived (salience < 0.05)
Not just another RAG
Beyond search. Structured understanding.
RAG finds similar chunks. Flat memory stores facts. Engram organizes knowledge.
Integrations
Integrate in minutes.
Add persistent memory to your agentic stack via MCP, Python SDK, or REST API. Model-agnostic by design.
# MCP Server (SSE transport)
# Endpoint: https://api.engram.so/mcp/sse
# Requires API key in Authorization header
{
"mcpServers": {
"engram": {
"transport": "sse",
"url": "https://api.engram.so/mcp/sse",
"headers": {
"Authorization": "Bearer eng_..."
}
}
}
}Pricing
Free to start. Open source forever.
Self-host the full engine for free. Use the cloud for managed hosting and dashboards.
Free
Everything you need to add memory to your AI agent.
- 3 contexts
- 1,000 bullets per context
- BYOK (bring your own LLM keys)
- Community support
- Dashboard access
- Claude MCP + ChatGPT Actions
Enterprise
Everything in Free, plus power features and dedicated infrastructure.
- Unlimited contexts
- 50,000 bullets per context
- Bullet editing & management
- Full graph explorer
- Dedicated tenant + data isolation
- Custom SLAs + dedicated support
- SSO / SAML + Audit logs
All plans include the open-source SDK. Self-host for free, forever.
Open Source
Fully open source. Not open-core.
The complete Engram engine — extraction, consolidation, materialization, concept graph — is MIT licensed. Self-host it, fork it, extend it. The cloud adds managed hosting and a dashboard, but the engine is the same.
pip install engram
Add memory to your agent in 5 minutes.
Free tier. No credit card. Open source.